概述
Map 是 Java 中的一种键值对集合类型的接口,它还提供了一些对数组进行排序、打印、和对 List 进行转换的静态方法。
常用的实现类有:
HashMap:哈希图。LinkedHashMap:链哈希图。TreeMap:树形哈希图。
HashMap
Java 中最常用的 Map 实现就是 HashMap。
数据结构
JDK8 中 HashMap 的数据结构是数组+链表+红黑树。
-
数组(
Node[] table):HashMap的核心是一个动态数组,用于存储键值对。这个数组被称为桶数组,其每个元素称为一个“桶”(Bucket),每个桶的索引是对键的哈希码通过哈希函数处理得到的。 -
链表/红黑树:为了解决哈希冲突(两个不同的键经过哈希函数计算得到相同的索引),
HashMap在每个桶中使用链表或红黑树来存储具有相同哈希值的元素。红黑树的查询效率是
O(logn),而链表是O(n)。在 Java 8 中,当链表长度超过阈值(默认为 8)并且桶的数量大于 64 时,链表会被转换为红黑树,以提高查询性能。
哈希函数
当向 HashMap 中添加一个键值对时,会使用哈希函数计算键的哈希码,确定其在数组中的位置,哈希函数的目标是尽量减少哈希冲突,保证元素能够均匀地分布在数组的每个位置上。
HashMap 的哈希函数如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
-
哈希码:当一个键值对通过
put()方法加入HashMap时,首先调用键的hashCode()方法计算其哈希码,这是一个整数值,用于确定元素在数组中的索引位置。 -
扰动处理:计算出的哈希码还会经过扰动处理(如位运算)来提高哈希分布的均匀性,减少哈希碰撞。如上方的无符号右移操作(
>>>)以及按位异或操作(^)。(h = key.hashCode()) ^ (h >>> 16)由于
hashCode()的返回值是int类型(也就是无符号的 32 位整形),通过h >>> 16可以获取哈希码的高 16 位的结果。接着进行按位异或操作,按位异或的结果是,高 16 位保持不变,低 16 位是取低 16 位与高 16 位进行异或的结果。
当从 HashMap 中获取元素时,也会使用哈希函数 hash() 计算键的位置,然后根据位置在数组、链表或者红黑树中查找元素。
扩容
HashMap 的初始容量是 16。随着元素的不断添加,HashMap 的容量(也就是桶数组的大小)可能不足,于是就需要进行扩容。阈值是 capacity * loadFactor,capacity 为容量,loadFactor 为负载因子,默认为 0.75。
扩容后的数组大小是原来的 2 倍,然后把原来的元素重新计算哈希值,放到新的数组中。
红黑树
红黑树(Red-Black Tree)是一种自平衡的二叉查找树(Binary Search Tree),广泛应用于需要快速插入、删除和查找操作的数据结构场景。
红黑树的每个节点都包含一个颜色属性,可以是红色或黑色,同时满足以下五个性质,这些性质确保了树大致上是平衡的,从而保证了操作的时间复杂度为 $O(log n)$,其中 $n$ 是树中节点的数量:
- 每个节点要么是红色,要么是黑色。
- 根节点是黑色。
- 所有叶子节点(NIL节点,空节点)都是黑色的。
- 如果一个节点是红色的,则它的两个子节点都是黑色的(也就是说,从每个叶子到根的所有路径上不能有两个连续的红色节点)。
- 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
这些性质使得红黑树在插入和删除节点后能够通过一系列的旋转和重新着色操作快速恢复平衡状态。
为什么不用二叉树?
二叉树容易出现极端情况,比如插入的数据是有序的,那么二叉树就会退化成链表,查询效率会变成 $O(n)$。
为什么不用平衡二叉树?
平衡二叉树比红黑树的要求更高,每个节点的左右子树的高度最多相差 1,这种高度的平衡保证了极佳的查找效率,但在进行插入和删除操作时,可能需要频繁地进行旋转来维持树的平衡,这在某些情况下可能导致更高的维护成本。
而红黑树是一种折中的方案,它在保证了树平衡的同时,插入和删除操作的性能也得到了保证,查询效率是 $O(log n)$。
红黑树的平衡
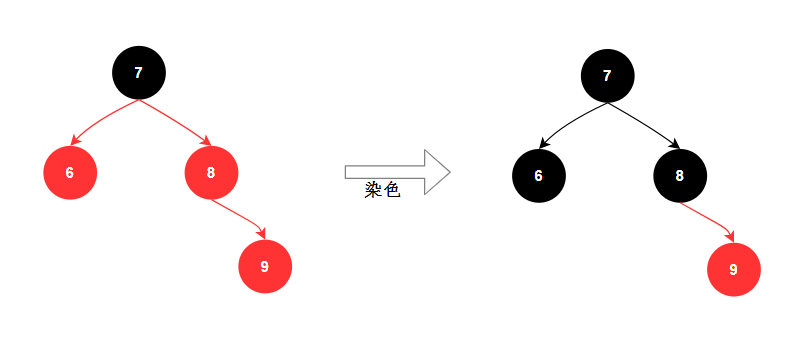
红黑树有两种方式保持平衡:旋转和染色。
- 旋转:旋转分为两种,左旋和右旋。
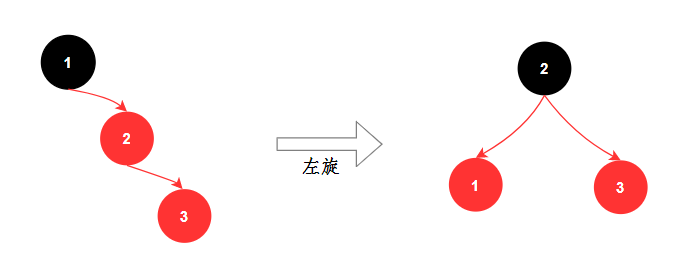
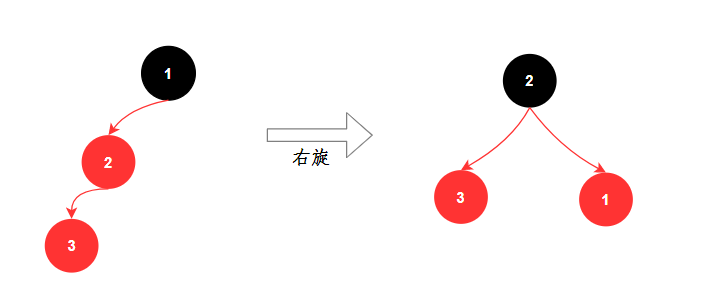
- 染⾊:
put 流程
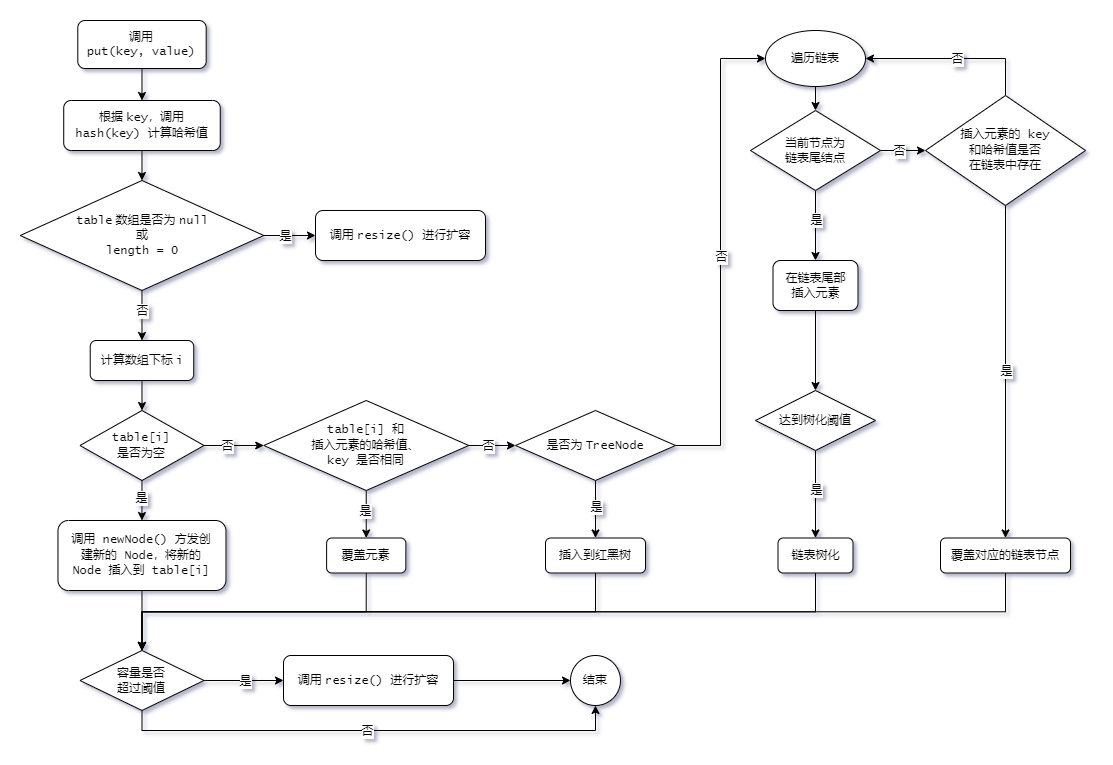
-
调用
hash(key)计算哈希值:static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } -
调用
resize()进行第一次扩容(对堆数组扩容):final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 扩容 /* 其余流程的代码在下方... */ } -
根据哈希值计算
key在数组中的下标:-
如果对应下标没有存放数据,则直接插入:
if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); -
如果对应下标已有数据,需要判断是否为相同的哈希值和
key,是则覆盖value,否则需要判断是否为树节点,是则向树中插入节点,否则向链表中插入数据:else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } }在此过程中,如果链表长度大于等于 8,就需要把链表转换为红黑树:
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash);
-
-
所有元素处理完后,还需要判断是否超过阈值
threshold,超过则扩容:if (++size > threshold) resize();
注意:如果只重写了
equals()没重写hashCode(),put()的时候会导致equals()相等的两个对象,hashCode()不相等。这种情况下,有可能会导致这两个equals()相等的对象会被放到不同的桶中,这样就会使得调用get()的时候,找不到对应的值。


评论